# Solution Storage
The HPE Ezmeral Data Fabric for Kubernetes provides the ability to run HPE Data Fabric services on top of Kubernetes as a set of pods. It allows you to create Data Platform Clusters for storing data and Tenants for running application such as spark jobs inside pods.Installing both the Tenant components and the Data Platform Cluster components, the HPE Data Fabric Platform runs as a fully native Kubernetes application. Deploying the Data Platform Cluster as part of the HPE Data Fabric for Kubernetes provides the following benefits:
Independent and elastic scaling of storage and compute
Ability to run different versions of Spark applications using the same data platform
Deployment of multiple environments with resource isolation and sharing as required
Solution components HPE External Ezmeral Data Fabric for Kubernetes are described at a high-level in Figure 7.
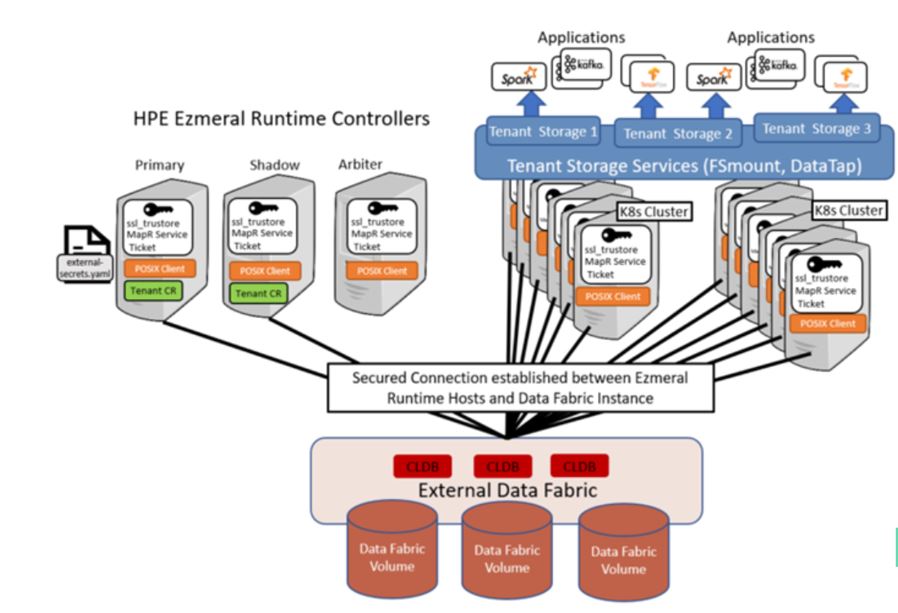
Figure 7. High-level HPE Ezmeral Data Fabric for Kubernetes architecture
# Configuring solution storage
Based on the required performance either solid-state disks or hard disk drives can be used, where it is consumed by HPE Ezmeral Runtime Enterprise ephemeral disk for Docker and optionally by compute nodes as boot devices. Kubernetes Storage Cluster running on HPE ProLiant DL380 Gen11 server’s local disk provides Persistent Volume (PV) for containers using the HPE CSI Driver.
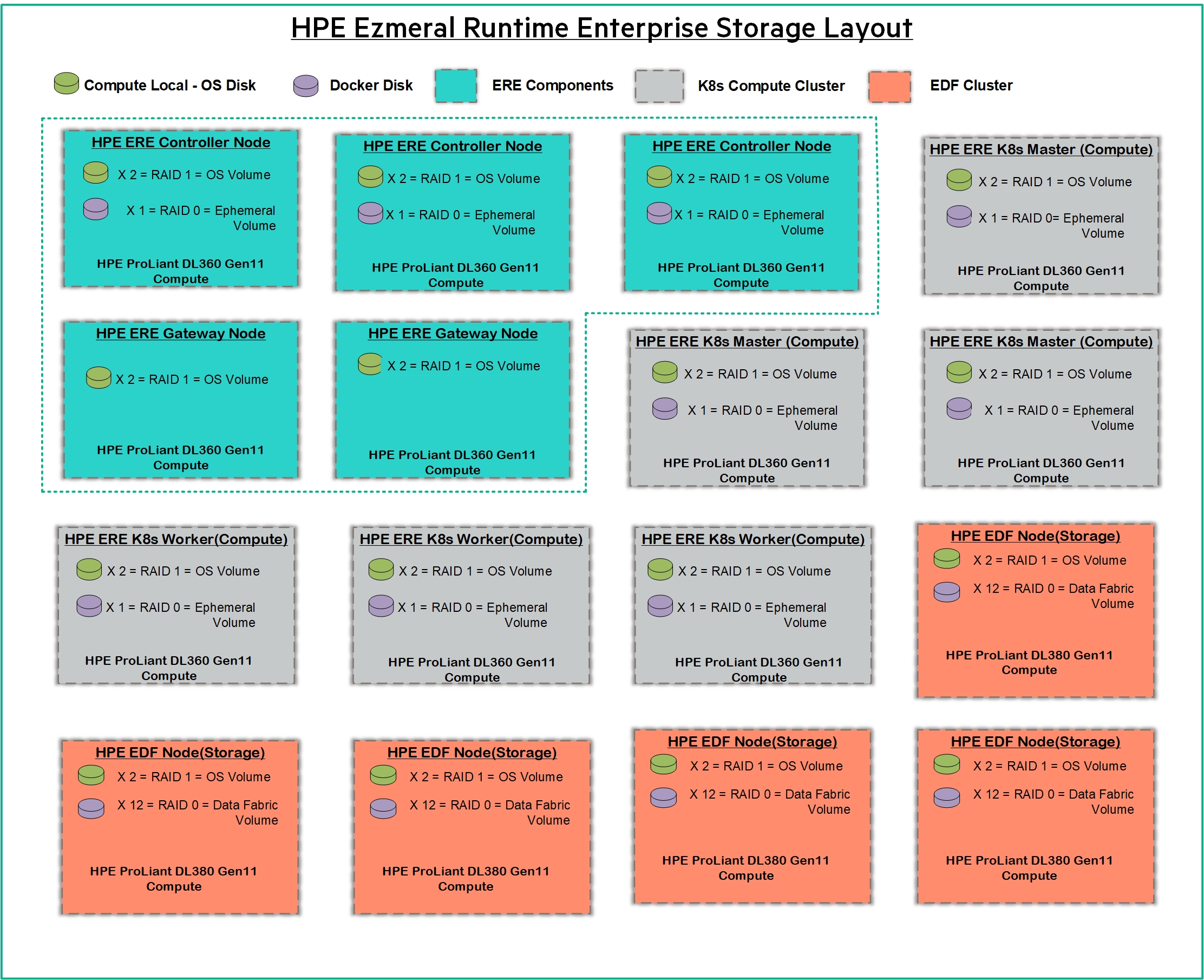
Figure 8. Logical storage layout within the solution