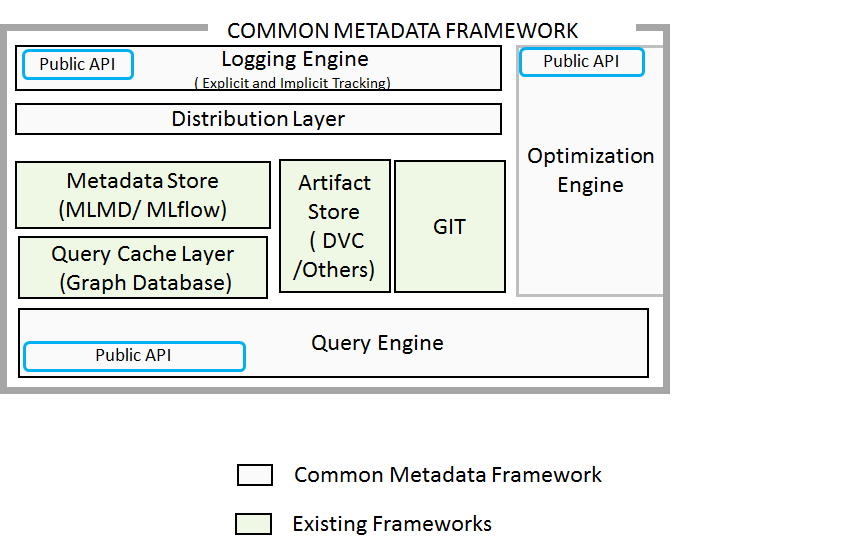
Architecture Overview¶
Interactions between different stages of a data pipeline are often challenging to track, particularly when artifacts move bidirectionally between stages and/or when the stages themselves are executed on different platforms. Additionally, each stage might have multiple dependencies, where the metadata and metrics produced by one stage influence the execution of the remainder of the pipeline. Capturing metadata during the execution of this pipeline is thus crucial for lineage tracking, provenance, and reproducibility.
The tracking of metadata through these complex pipelines has multiple challenges, including:
- Each stage in the pipeline could be executed in a different data center or at an edge site with intermittent connection to the core data center.
- Each stage in the pipeline could be managed by different teams.
- The artifacts (input or output) need to be uniquely identified across different sites and multiple pipelines.
The Common Metadata Framework (CMF) addresses the problems associated with tracking pipeline metadata from distributed sites and tracks code, data, and metadata together for end-to-end traceability.
The framework automatically tracks the code version as part of the pipeline's metadata execution. Additionally, data artifacts are also versioned automatically using a data versioning framework (like DVC), with the data version stored along with the code as metadata. The framework stores (1) the git commit ID of the metadata file associated with the artifact and (2) a hash of the artifact's content. The framework provides APIs to track the parameters and other metadata of pipelines. From the stored metadata, users can identify the hyperparameters, code version, and artifact version used for the experiment.
Identifying an artifact by its hash allows the framework to uniquely identify it across distributed sites. These can subsequently be merged into a central repository, enabling a single source of truth for global metadata across multiple sites.
CMF thus provides a git-like experience for metadata, enabling users to push their local metadata to the remote repository, where it is merged to create the global metadata, and pull metadata from the global repository to the local environment, to create a local view containing only the metadata of interest.
The framework can be used to track various types of data-oriented pipelines, for example, data processing or training AI models.