Getting started with CMF¤
Purpose and Scope¤
This document provides a comprehensive overview of the Common Metadata Framework (CMF), which implements a system for collecting, storing, and querying metadata associated with Machine Learning (ML) pipelines. CMF adopts a data-first approach where all artifacts (datasets, ML models, and performance metrics) are versioned and identified by their content hash, enabling distributed metadata tracking and collaboration across ML teams.
For detailed API documentation, see Core Library (cmflib). For deployment instructions, see Installation & Setup. For web user interface details, see CMF GUI.
System Architecture¤
CMF is designed as a distributed system that enables ML teams to track pipeline metadata locally and synchronize with a central server. The framework automatically tracks code versions, data artifacts, and execution metadata to provide end-to-end traceability of ML experiments.
Common Metadata Framework (CMF) has the following components:
- cmflib: A Python library that captures and tracks metadata throughout your ML pipeline, including datasets, models, and metrics. It provides APIs for both logging metadata during execution and querying it later for analysis.
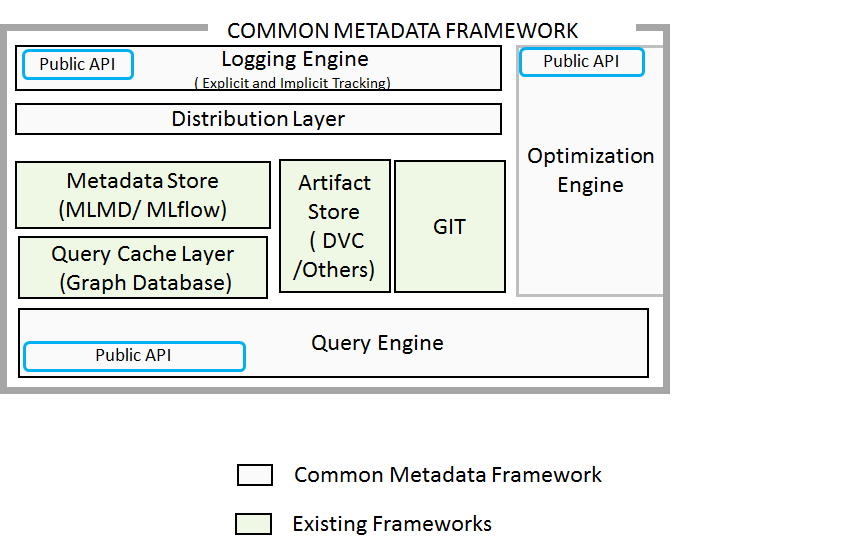
- CMF Client: A command-line tool that synchronizes metadata with the
CMF Server, manages artifact transfers to and from storage repositories, and integrates with Git for version control. - CMF Server with GUI: A centralized server that aggregates metadata from multiple clients and provides a web-based graphical interface for visualizing pipeline executions, artifacts, and lineage relationships, enabling teams to collaborate effectively.
- Central Artifact Repositories: Storage backends (such as AWS S3, MinIO, or SSH-based storage) that host your datasets, models, and other pipeline artifacts.
User Interaction Flow¤
%%{init: {'theme':'base', 'themeVariables': { 'primaryColor':'#f5f5f5','primaryTextColor':'#37474f','primaryBorderColor':'#90a4ae','lineColor':'#78909c','fontSize':'15px','fontFamily':'system-ui, -apple-system, sans-serif'}}}%%
flowchart TB
subgraph CLIUSER["👩💻 ML Engineer / Data Scientist Workflow"]
direction TB
CLI1([1. Write ML Pipeline Code])
CLI2([2. Log Metadata with cmflib])
CLI3([3. Run Pipeline Locally])
CLI4([4. Push Metadata to Server])
CLI5([5. Push Artifacts to Storage])
CLI6([6. Pull Metadata from Server])
CLI7([7. Pull Artifacts from Server])
CLI1 --> CLI2 --> CLI3 --> CLI4 --> CLI5
CLI6 -.->|Collaborate| CLI2
CLI6 -.->|Collaborate| CLI2
end
subgraph WEBUSER["👥 Team Members / Stakeholders Workflow"]
direction TB
WEB1([1. Access Web Interface])
WEB2([2. Browse Pipelines & Executions])
WEB3([3. View Lineage Graphs])
WEB4([4. Analyze Metrics & Models])
WEB5([5. Compare Experiments])
WEB1 --> WEB2 --> WEB3 --> WEB4 --> WEB5
end
subgraph INFRA["🔧 CMF Infrastructure"]
direction LR
SERVER[CMF Server]
DB[(Metadata Store)]
STORAGE[Artifact Storage<br/><i>S3/MinIO/SSH</i>]
SERVER <--> DB
end
CLI4 -.->|cmf metadata push| SERVER
CLI5 -.->|cmf artifact push| STORAGE
CLI6 -.->|cmf metadata pull| SERVER
WEB1 -.->|HTTPS| SERVER
SERVER -.->|Query| DB
style CLI1 fill:#e1f5fe,stroke:#0288d1,stroke-width:2px,color:#01579b
style CLI2 fill:#e1f5fe,stroke:#0288d1,stroke-width:2px,color:#01579b
style CLI3 fill:#e1f5fe,stroke:#0288d1,stroke-width:2px,color:#01579b
style CLI4 fill:#b3e5fc,stroke:#0288d1,stroke-width:2px,color:#01579b
style CLI5 fill:#b3e5fc,stroke:#0288d1,stroke-width:2px,color:#01579b
style CLI6 fill:#b3e5fc,stroke:#0288d1,stroke-width:2px,color:#01579b
style WEB1 fill:#f3e5f5,stroke:#8e24aa,stroke-width:2px,color:#4a148c
style WEB2 fill:#f3e5f5,stroke:#8e24aa,stroke-width:2px,color:#4a148c
style WEB3 fill:#f3e5f5,stroke:#8e24aa,stroke-width:2px,color:#4a148c
style WEB4 fill:#f3e5f5,stroke:#8e24aa,stroke-width:2px,color:#4a148c
style WEB5 fill:#f3e5f5,stroke:#8e24aa,stroke-width:2px,color:#4a148c
style SERVER fill:#e8f5e9,stroke:#43a047,stroke-width:2.5px,color:#1b5e20
style DB fill:#fff3e0,stroke:#fb8c00,stroke-width:2px,color:#e65100
style STORAGE fill:#fce4ec,stroke:#d81b60,stroke-width:2px,color:#880e4f
style CLIUSER fill:#f1f8ff,stroke:#0366d6,stroke-width:3px,color:#0366d6
style WEBUSER fill:#fef3ff,stroke:#8e24aa,stroke-width:3px,color:#8e24aa
style INFRA fill:#f6f8fa,stroke:#586069,stroke-width:2px,color:#586069
linkStyle default stroke:#78909c,stroke-width:2pxCore Abstractions¤
CMF uses three primary abstractions to model ML pipeline metadata:
| Abstraction | Purpose | Implementation |
|---|---|---|
| Pipeline | Groups related stages and executions | Identified by name in cmflib.cmf.Cmf constructor |
| Context | Represents a stage type (e.g., "train", "test") | Created via create_context() method |
| Execution | Represents a specific run of a stage | Created via create_execution() method |
%%{init: {'theme':'base', 'themeVariables': { 'primaryColor':'#e3f2fd','primaryTextColor':'#546e7a','primaryBorderColor':'#90caf9','lineColor':'#cfd8dc','secondaryColor':'#f3e5f5','tertiaryColor':'#e8f5e9','fontSize':'13px','fontFamily':'system-ui, -apple-system, sans-serif'}}}%%
flowchart LR
PIPELINE([Pipeline<br/>'mnist_experiment'])
CONTEXT1([Context<br/>'download'])
CONTEXT2([Context<br/>'train'])
CONTEXT3([Context<br/>'test'])
EXEC1[/Execution<br/>'download_data'/]
EXEC2[/Execution<br/>'train_model'/]
EXEC3[/Execution<br/>'evaluate_model'/]
DATASET1[(Dataset<br/>'raw_data.csv')]
MODEL1[(Model<br/>'trained_model.pkl')]
METRICS1[(Metrics<br/>'accuracy: 0.95')]
PIPELINE -.-> CONTEXT1
PIPELINE -.-> CONTEXT2
PIPELINE -.-> CONTEXT3
CONTEXT1 -.-> EXEC1
CONTEXT2 -.-> EXEC2
CONTEXT3 -.-> EXEC3
EXEC1 -.-> DATASET1
EXEC2 -.-> MODEL1
EXEC3 -.-> METRICS1
style PIPELINE fill:#e3f2fd,stroke:#90caf9,stroke-width:2px,color:#546e7a
style CONTEXT1 fill:#fff8e1,stroke:#ffcc80,stroke-width:2px,color:#d84315
style CONTEXT2 fill:#fff8e1,stroke:#ffcc80,stroke-width:2px,color:#d84315
style CONTEXT3 fill:#fff8e1,stroke:#ffcc80,stroke-width:2px,color:#d84315
style EXEC1 fill:#f3e5f5,stroke:#ce93d8,stroke-width:2px,color:#7b1fa2
style EXEC2 fill:#f3e5f5,stroke:#ce93d8,stroke-width:2px,color:#7b1fa2
style EXEC3 fill:#f3e5f5,stroke:#ce93d8,stroke-width:2px,color:#7b1fa2
style DATASET1 fill:#e8f5e9,stroke:#a5d6a7,stroke-width:2px,color:#388e3c
style MODEL1 fill:#e8f5e9,stroke:#a5d6a7,stroke-width:2px,color:#388e3c
style METRICS1 fill:#e8f5e9,stroke:#a5d6a7,stroke-width:2px,color:#388e3c
linkStyle default stroke:#cfd8dc,stroke-width:1.5px,color:#cfd8dc,fill:noneKey Features¤
Distributed Metadata Tracking¤
CMF enables distributed teams to work independently while maintaining consistent metadata through content-addressable artifacts and Git-like synchronization:
- Local Development: Each developer works with a local MLMD database
- Content Hashing: All artifacts are identified by their content hash for universal identification
- Synchronization:
cmf metadata push/pullcommands sync with central server - Artifact Storage: Support for MinIO, Amazon S3, SSH, and local storage backends
Automatic Version Tracking¤
CMF automatically captures:
- Code Version: Git commit IDs for reproducibility
- Data Version: DVC-managed artifact content hashes
- Environment: Execution parameters and custom properties
- Lineage: Input/output relationships between executions
Query and Visualization¤
The system provides multiple interfaces for exploring metadata:
- Programmatic:
CmfQueryclass for custom queries - Web UI: React-based interface for browsing artifacts and executions
- Lineage Graphs: D3.js visualizations showing data flow between pipeline stages
- TensorBoard Integration: Training metrics visualization
- MCP Server: AI assistant integration for natural language metadata queries
AI-Powered Metadata Access¤
The CMF MCP Server enables AI assistants like Claude, GitHub Copilot, and Cursor to interact with your CMF metadata using natural language:
- Natural Language Queries: Ask questions like "What pipelines are available?" or "Show me the execution lineage"
- Model Context Protocol: Standards-based integration with any MCP-compatible AI assistant
- Multi-Server Support: Query across development, staging, and production environments
- Production Ready: Containerized deployment with health checks and monitoring
See the MCP Server documentation to get started with AI-powered metadata exploration.